引用本文:
金交羽, 严小璇, 刘亚平, 蓝文贤, 王春喜, 许斌, 曹春阳. 胞嘧啶脱氨基化酶APOBEC3家族及其与核酸复合物结构研究进展[J]. 化学学报,
2019, 77(11): 1089-1098.
doi:
10.6023/A19080296 Citation:
Jin Jiaoyu, Yan Xiaoxuan, Liu Yaping, Lan Wenxian, Wang Chunxi, Xu Bin, Cao Chunyang. Recent Advances in the Structural Studies on Cytosine Deaminase APOBEC3 Family Members and Their Nucleic Acid Complexes[J]. Acta Chimica Sinica,
2019, 77(11): 1089-1098.
doi:
10.6023/A19080296
Received Date:
07 August 2019 Available Online:
15 November 2019
Abstract:
Apolipoprotein B mRNA catalytically edited protein APOBEC3 (A3) is a family of proteins in the intracellular retrotransposon defense system, including seven members APOBEC3A (A3A), APOBEC3B (A3B), APOBEC3C (A3C), APOBEC3DE (A3DE), APOBEC3F (A3F), APOBEC3G (A3G) and APOBEC3H (A3H) encoded in a tandem array on human chromosome 22. They deaminate cytosine in single-stranded DNA and RNA substrates, which play a variety of roles in human health and disease. Among them, A3DE, A3F, A3G and A3H restrict replication of human immunodeficiency virus-1 (HIV-1) in strains lacking the virus infectivity factor protein (Vif) by deaminating cytidine in virus cDNA. Subsequent replication of the virus cDNA generates the hallmark G-to-A hyper-mutations, causing proviral inactivation. HIV-1 develops countermeasures to antagonize this intrinsic host defense response. Its Vif protein facilitates polyubiquitination of A3 members by recruiting an E3 ubiquitin ligase complex, which results in the proteasomal degradation of A3 proteins. To better understand the deamination mechanism of A3 proteins, we here reviewed the research progress on the structures of free A3 family members and their complexes with single-stranded DNA or double-stranded RNA. It includes the structures of the apo-forms of N- and/or C-termini domains of A3A, A3B, A3C, A3F, A3G and A3H, or the chimeric forms of their functional domains, and their complexes with nucleic acids, which demonstrate the basis of how A3 proteins to identify target base cytosine in hot motifs 5'-TC or 5'-CC in DNA, and then to conduct catalytic deamination. We simply described how the key residues of A3 members are involved in DNA or RNA interactions, the common properties of their structures, and their interactions with DNA or RNA. We partially discussed the interactions between A3 proteins and Vif, therefore, this review might be helpful to rationally design anti-virus drugs to disrupt these interactions. We finally suggested the new research directions about how to make full-length A3 proteins containing N-terminal CD1 and C-terminal CD2 domains, and how to study the interactions between these full-length A3 proteins and nucleic acids through cryo-EM and other techniques.
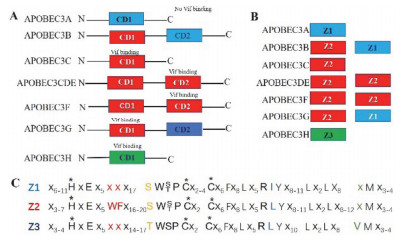
Figure 1.
Classification and nomination of the functional domain of A3 family members. (A) The classification of CD1 and CD2 domains of A3 family members; (B) A3 family is classified according to Z1, Z2, Z3; (C) Sequence alignment of three types of Z regions[2], in which residues ligated with Zn2+were marked with star
Figure 3.
The sequence alignment of A3 family protein. Clustal Omega amino acids alignment showing secondary structures (α-helices, β-strand and loop). In A3 members, conserved residues H70, W98 and Y130 (in A3A) are all involved in DNA interactions
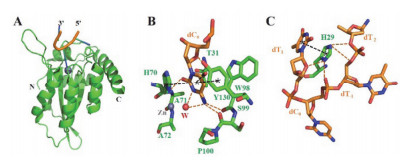
Figure 4.
The crystal structure of A3A E72A/C171A variant in complex with ssDNA (PDB code 5KEG)
[50]. (A) Complex structure was displayed in cartoon mode; (B) Interactions between A3A and the target nucleotide base (dC0); (C) Interactions between H29 side chain and the substrate DNA. A3A structure is shown in green, and the DNA is shown in orange; in all picture, Zn2+ ion and water (W) are indicated by grey and red spheres, hydrogen bonds and π-orbital interaction are depicted by orange and black dashed lines. The structures of residues and bases in (B) and (C) were shown in stick mode
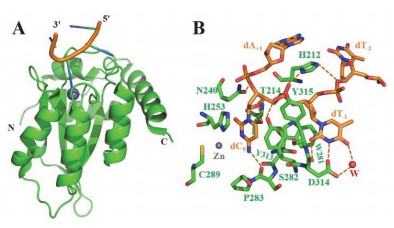
Figure 5.
Crystal structure of chimeric A3B variant in complex with ssDNA (PDB code 5TD5)[51]. (A) Complex structure was displayed in cartoon mode; (B) Interactions between A3B active site and DNA. A3B is in green, DNA is shown in orange, Zn2+ ion and water (W) are indicated by grey and red spheres, and hydrogen bonds is depicted by orange dashed lines, respectively
Figure 6.
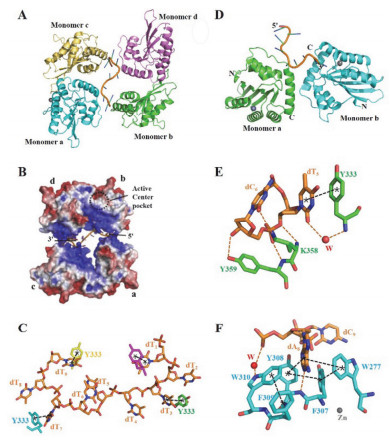
Crystal structure of A3B in complex with ssDNA[52, 53]. (A) Crystal structure of A3F-CD2 tetramer and substrate DNA(PDB code 5W2M), four A3F-CD2 monomers are in green, lavender, golden yellow, light blue, respectively, and DNA is in orange; (B) Electrostatic surface of crystal structure of A3F-CD2 in complex with DNA (blue is positive charge, red is negative charge). (C) Residue Y333 in each A3F-CD2 (cyan, green, pink and yellow) stacks with base dT in DNA (orange). (D) Crystal structure of chimeric A3Fc-CD2 dimer in complex with ssDNA (PDB code 5ZVA), two A3Fc-CD2 monomers are in green and light blue, respectively; (E) Residues Y333, K358 and K359 in A3Fc-CD2 monomer a form the first DNA binding site; (F) Residues W277, Y307, Y308, F309 and W310 in A3Fc-CD2 monomer b form the second DNA binding site. Zn2+ion and water (W) are indicated by spheres colored grey and red, respectively, hydrogen bonds and π-orbital interaction are depicted by orange and black dashed lines, respectively
Figure 7.
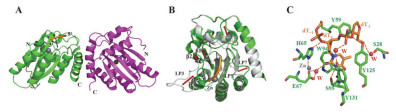
The crystal structure of rA3G-CD1 in complex with ssDNA[54]. (A) Complex structure of rA3G-CD2 dimer and substrate DNA (orange) (PDB code 5K83); The two rA3G-CD1monomers are shown in green and purple, respectively. (B) Superimposition of bound rA3G-CD1 (green) and apo rA3G-CD1 (grey). loop-1, loop-3, loop-5 and loop-7 were referred as LP1, LP3, LP5 and LP7, respectively. Red arrows indicate the major conformational shifts of loop, β1and β2 upon DNA binding. (C) Interaction between poly-dT and zinc ion binding pocket. In all figures, DNA is in orange. Zn2+ion and water (W) are indicated by spheres colored grey and red, respectively, hydrogen bonds and π-orbital interaction are depicted by orange and black dashed lines, respectively
Figure 8.
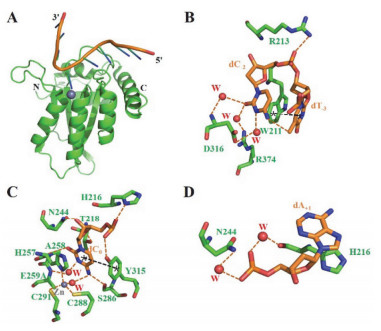
The crystal structure of A3G-CD2 variant A3G-CDT2* in complex with ssDNA (PDB code 6BUX)
[55]. (A) Complex structure was displayed in cartoon mode; (B, C, D) Interactions between bases dC-2, dT-3, dC0 and dA+1 (in orange stick) in DNA and residues (in green stick) in A3G-CDT2*. In all picture, A3G-CDT2* is in green, and DNA is in orange; Zn2+ion and water (W) are indicated by grey and red spheres, respectively, hydrogen bonds and π-orbital interaction are depicted by orange and black dashed lines, respectively
Figure 9.
NMR solution structure of A3G-CD2 and ssDNA[56]. (A) Deamination product TCUU6I ssDNA binds to A3G-CD2 in a CCC mode (PDB code 6K3J). (B) Deamination product TCUC6I ssDNA binds to A3G-CD2 in a TCC mode (PDB code 6K3K). In all picture, A3G-CD2 is shown in green, and the DNA is shown in orange, Zn2+ion is indicated by grey spheres
Figure 10.
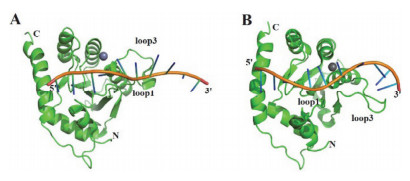
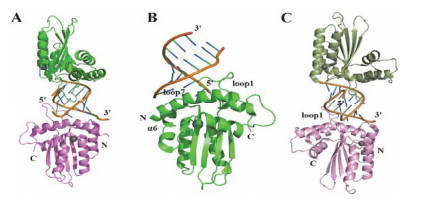
Crystal complex structures of A3H from different hosts and dsRNA[57~59]. (A) Complex structure of pig-tailed macaque A3H and dsRNA (PDB code 5W3V), two A3H monomers are in green and purple, and dsRNA is in orange, respectively; (B) Complex structure of human A3H and dsRNA (PDB code 6BOB), A3H is in green and dsRNA is in orange, respectively. (C) Complex structure of chimpanzee A3H and dsRNA (PDB code 5Z98), two A3H monomers are in grass and lilac, dsRNA is in orange, respectively. In all pictures, Zn2+ion is indicated by grey spheres
Larue, R. S.; Andresdottir, V.; Blanchard, Y.; Conticello, S. G.; Derse, D.; Emerman, M.; Greene, W. C.; Jonsson, S. R.; Landau, N. R.; Lochelt, M.; Malik, H. S.; Malim, M. H.; Munk, C.; O'Brien, S. J.; Pathak, V. K.; Strebel, K.; Wain-Hobson, S.; Yu, X. F.; Yuhki, N.; Harris, R. S. J. Virol.2009, 83, 494. doi: 10.1128/JVI.01976-08
Bergeron, J. R.; Huthoff, H.; Veselkov, D. A.; Beavil, R. L.; Sanderson, M. R. PLoS Pathog.2010, 6, e1000925. doi: 10.1371/journal.ppat.1000925
[41]
Reingewertz, T. H.; Shalev, D. E.; Friedler, A. Protein Pept. Lett.2010, 17, 988. doi: 10.2174/092986610791498876
[42]
Liddament, M. T.; Brown, W. L.; Schumacher, A. J.; Harris, R. S. Curr. Biol. 2004, 14, 1385. doi: 10.1016/j.cub.2004.06.050
[43]
Lu, Z.; Bergeron, J. R. C.; AtkinsLu, Z.; Bergeron, J. R. C.; Atkinson, R. A.; Schaller, T.; Veselkov, D. A.; Oregioni, A. Open. Biol.2013, 3, 130100. doi: 10.1098/rsob.130100
[44]
Luo, K.; Xiao, Z.; Ehrlich, E.; Yu, Y.; Liu, B.; Zheng, S. Proc. Natl. Acad. Sci. U. S. A. 2005, 102, 11444. doi: 10.1073/pnas.0502440102
[45]
Stenglein, M. D.; Burns, M. B.; Li, M.; Lengyel, J.; Harris, R. S. Nat. Struct. Mol. Biol.2010, 17, 222. doi: 10.1038/nsmb.1744
[46]
Chelico, L.; Pham, P.; Calabrese, P.; Goodman, M. F. Nat. Struct. Mol. Biol.2006, 13, 392. doi: 10.1038/nsmb1086
Kouno, T.; Silvas, T. V.; Hilbert, B. J.; Shandilya, S. M. D.; Bohn, M. F.; Kelch, B. A.; Royer, W. E.; Somasundaran, M.; Kurt Yilmaz, N.; Matsuo, H.; Schiffer, C. A. Nat. Commun.2017, 8, 15024. doi: 10.1038/ncomms15024
[51]
Shi, K.; Carpenter, M. A.; Banerjee, S.; Shaban, N. M.; Kurahashi, K.; Salamango, D. J.; McCann, J. L.; Starrett, G. J.; Duffy, J. V.; Demir, O.; Amaro, R. E.; Harki, D. A.; Harris, R. S.; Aihara, H. Nat. Struct Mol. Biol.2017, 24, 131. doi: 10.1038/nsmb.3344
[52]
Fang, Y.; Xiao, X.; Li, S.; Wolfe, A.; Chen, X. S. J. Mol. Biol. 2018, 430, 87. doi: 10.1016/j.jmb.2017.11.007
[53]
Cheng, C.; Zhang, T.; Wang, C. X.; Lan, W.; Ding, J.; Cao, C. Y. Chin. J. Chem. 2018, 36, 1241. doi: 10.1002/cjoc.201800508
[54]
Xiao, X.; Li, S. X.; Yang, H.; Chen, X. S. Nat. Commun. 2016, 7, 12193. doi: 10.1038/ncomms12193
[55]
Maiti, A.; Myint, W.; Kanai, T.; Delviks-Frankenberry, K.; Sierra Rodriguez, C.; Pathak, V. K.; Schiffer, C. A.; Matsuo, H. Nat. Commun.2018, 9, 2460. doi: 10.1038/s41467-018-04872-8
[56]
Yan, X. X.; Lan, W. X.; Wang, C. X.; Cao, C. Y. Chem. Asian J.2019, 14, 2235. doi: 10.1002/asia.201900480
[57]
Bohn, J. A.; Thummar, K.; York, A.; Raymond, A.; Brown, W. C.; Bieniasz, P. D.; Hatziioannou, T.; Smith, J. L. Nat. Commun.2017, 8, 1021. doi: 10.1038/s41467-017-01309-6
[58]
Nadine, M. S.; Shi, K.; Lauer, K. V.; Brown, W. L.; Aihara, H.; Harris, R. S. Mol. Cell2018, 69, 75. doi: 10.1016/j.molcel.2017.12.010
Figure 1
Classification and nomination of the functional domain of A3 family members. (A) The classification of CD1 and CD2 domains of A3 family members; (B) A3 family is classified according to Z1, Z2, Z3; (C) Sequence alignment of three types of Z regions[2], in which residues ligated with Zn2+were marked with star
Figure 3
The sequence alignment of A3 family protein. Clustal Omega amino acids alignment showing secondary structures (α-helices, β-strand and loop). In A3 members, conserved residues H70, W98 and Y130 (in A3A) are all involved in DNA interactions
Figure 4
The crystal structure of A3A E72A/C171A variant in complex with ssDNA (PDB code 5KEG)
[50]. (A) Complex structure was displayed in cartoon mode; (B) Interactions between A3A and the target nucleotide base (dC0); (C) Interactions between H29 side chain and the substrate DNA. A3A structure is shown in green, and the DNA is shown in orange; in all picture, Zn2+ ion and water (W) are indicated by grey and red spheres, hydrogen bonds and π-orbital interaction are depicted by orange and black dashed lines. The structures of residues and bases in (B) and (C) were shown in stick mode
Figure 5
Crystal structure of chimeric A3B variant in complex with ssDNA (PDB code 5TD5)[51]. (A) Complex structure was displayed in cartoon mode; (B) Interactions between A3B active site and DNA. A3B is in green, DNA is shown in orange, Zn2+ ion and water (W) are indicated by grey and red spheres, and hydrogen bonds is depicted by orange dashed lines, respectively
Figure 6
Crystal structure of A3B in complex with ssDNA[52, 53]. (A) Crystal structure of A3F-CD2 tetramer and substrate DNA(PDB code 5W2M), four A3F-CD2 monomers are in green, lavender, golden yellow, light blue, respectively, and DNA is in orange; (B) Electrostatic surface of crystal structure of A3F-CD2 in complex with DNA (blue is positive charge, red is negative charge). (C) Residue Y333 in each A3F-CD2 (cyan, green, pink and yellow) stacks with base dT in DNA (orange). (D) Crystal structure of chimeric A3Fc-CD2 dimer in complex with ssDNA (PDB code 5ZVA), two A3Fc-CD2 monomers are in green and light blue, respectively; (E) Residues Y333, K358 and K359 in A3Fc-CD2 monomer a form the first DNA binding site; (F) Residues W277, Y307, Y308, F309 and W310 in A3Fc-CD2 monomer b form the second DNA binding site. Zn2+ion and water (W) are indicated by spheres colored grey and red, respectively, hydrogen bonds and π-orbital interaction are depicted by orange and black dashed lines, respectively
Figure 7
The crystal structure of rA3G-CD1 in complex with ssDNA[54]. (A) Complex structure of rA3G-CD2 dimer and substrate DNA (orange) (PDB code 5K83); The two rA3G-CD1monomers are shown in green and purple, respectively. (B) Superimposition of bound rA3G-CD1 (green) and apo rA3G-CD1 (grey). loop-1, loop-3, loop-5 and loop-7 were referred as LP1, LP3, LP5 and LP7, respectively. Red arrows indicate the major conformational shifts of loop, β1and β2 upon DNA binding. (C) Interaction between poly-dT and zinc ion binding pocket. In all figures, DNA is in orange. Zn2+ion and water (W) are indicated by spheres colored grey and red, respectively, hydrogen bonds and π-orbital interaction are depicted by orange and black dashed lines, respectively
Figure 8
The crystal structure of A3G-CD2 variant A3G-CDT2* in complex with ssDNA (PDB code 6BUX)
[55]. (A) Complex structure was displayed in cartoon mode; (B, C, D) Interactions between bases dC-2, dT-3, dC0 and dA+1 (in orange stick) in DNA and residues (in green stick) in A3G-CDT2*. In all picture, A3G-CDT2* is in green, and DNA is in orange; Zn2+ion and water (W) are indicated by grey and red spheres, respectively, hydrogen bonds and π-orbital interaction are depicted by orange and black dashed lines, respectively
Figure 9
NMR solution structure of A3G-CD2 and ssDNA[56]. (A) Deamination product TCUU6I ssDNA binds to A3G-CD2 in a CCC mode (PDB code 6K3J). (B) Deamination product TCUC6I ssDNA binds to A3G-CD2 in a TCC mode (PDB code 6K3K). In all picture, A3G-CD2 is shown in green, and the DNA is shown in orange, Zn2+ion is indicated by grey spheres
Figure 10
Crystal complex structures of A3H from different hosts and dsRNA[57~59]. (A) Complex structure of pig-tailed macaque A3H and dsRNA (PDB code 5W3V), two A3H monomers are in green and purple, and dsRNA is in orange, respectively; (B) Complex structure of human A3H and dsRNA (PDB code 6BOB), A3H is in green and dsRNA is in orange, respectively. (C) Complex structure of chimpanzee A3H and dsRNA (PDB code 5Z98), two A3H monomers are in grass and lilac, dsRNA is in orange, respectively. In all pictures, Zn2+ion is indicated by grey spheres

 下载:
下载:


 下载:
下载:











 下载:
下载:
