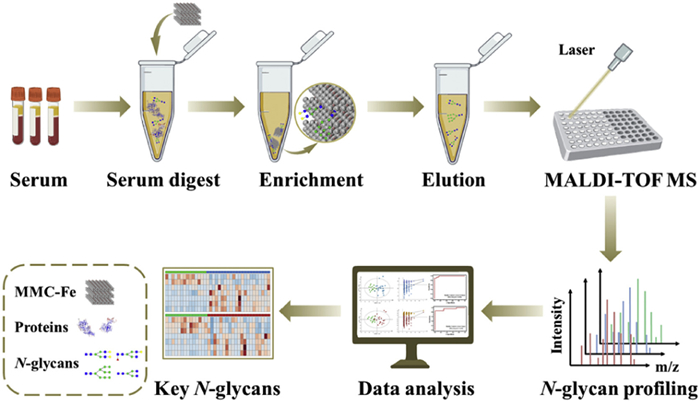
Figure 1.
Schematic overview of serum N-glycans enrichment by MMC-Fe and MALDI-TOF MS profiling analysis.

Liver diseases can cause severe physical and psychological harm, leading to a significant global health impact. Especially the incidence and mortality rates of liver cirrhosis and liver cancer are alarmingly high, resulting in millions of annual fatalities [1,2]. Liver cirrhosis is a common chronic liver disease in clinical practice, with diverse etiopathogenisis and a long incubation period. It is difficult to detect obvious symptoms in the early stages of liver cirrhosis, but long-term damage to the human system ultimately leads to various complications, such as thrombus, gastrointestinal bleeding and cancer, until death [3,4]. As for liver cancer, the majority of cases are diagnosed in the late stage, but it is difficult to cure clinically at this time [5,6]. Timely detection of liver cancer is of paramount importance, as it significantly enhances survival chances, achieving a five-year survival rate of approximately 70% − a marked improvement compared to late-stage discovery [7–9]. However, the current conventional clinical detection for these liver diseases still heavily relies on histological and imaging examinations, which are invasive, costly, and frequently lack the requisite objectivity for timely detection. Therefore, it will be great to develop a powerful tool with high accuracy, high throughput, rapid processing, user-friendly operation, and non-invasive capabilities. Such a tool would enhance the precision of liver disease detection, ultimately improving survival rates and prognosis.
Glycosylation, a common and critical post-translational modification (PTM) of proteins, involves more than 7000 highly conserved N-glycosylated proteins in humans [10]. N-Glycosylation refers to the covalent binding process between the hemiacetal hydroxyl group of oligosaccharides and the amino groups of Asn residues in the nascent proteins sequence Asn X-Ser/Thr (X refers to amino acids except proline) [11]. The transportation, modification, and processing of N-glycans principally occur in the endoplasmic reticulum (ER) and Golgi apparatus, and the resulting N-glycans have diverse structures and various biological functions, which can reflect numerous physiological and pathological processes [12]. Notably, the expression pattern of glycosyltransferases in cancer cells differs significantly from that of normal cells. Therefore, the glycan structure of glycoproteins changes with disease progression, resulting in the objective indicator of glyco-biomarkers [13–15]. It has been known that the alterations of N-glycans, such as sialylation and fucosylation, are closely related to various disease processes. For example, alpha fetoprotein (AFP) is broadly recognized as a biomarker for the detection of hepatocellular carcinoma (HCC), and its fucosylated form (AFP-L3 fraction) is also a significant serum biomarker approved by the FDA for early diagnosis of HCC [16–18]. Compared to AFP, AFP L3 can further differentiate between hepatitis, liver cirrhosis and liver cancer, thereby reducing the possibility of false positives in independent diagnosis of AFP [19]. Nevertheless, widespread meta-analysis indicates that although AFP-L3% has high specificity for early diagnosis of liver cancer, its sensitivity is low and unstable (about 45%–90%) [20–22]. Compared to protein biomarkers, biomarkers explored based on the change of glycan expression level and conformation may can achieve finer disease stratification at higher sensitivity and specificity. However, there are few comprehensive studies on glycomics analysis or glyco-biomarkers discovery related to liver diseases. Therefore, further exploration and characterization of N-glycans in serum are of great significance for the precise detection of liver diseases.
Owing to the advantages of fast detection, high throughput, and sensitivity, matrix-assisted laser desorption/ionization time-of-flight mass spectrometry (MALDI-TOF MS) shows great potential in the detection of large-scale clinical samples [23,24]. Recently, MALDI-TOF MS were extensively applied in the development of detection tools, leveraging metabolomics and proteomics researches. For instance, Zhang et al. utilized porous perovskite oxide microrods in conjunction with MALDI-TOF MS to efficiently generate metabolic fingerprints from numerous serum samples, enabling the establishment of a robust diagnostic model for Alzheimer's disease [25]. Lazari et al. reported plasma proteomic fingerprint profiles through a combination of MALDI-TOF MS and machine learning to predict high/low-risk COVID-19 cases [26]. However, despite the significant potential demonstrated by glycans exploration in disease-related research, there are a few reports on conducting large-scale glycans screening for the development of disease diagnostic tools. In earlier years, our research group developed various carbon sources such as polydopamine [27], metal-organic frameworks [28,29], for preparing mesoporous carbon to achieve glycan enrichment. Recently, we proposed a more convenient and high-yield preparation of carbonized mesopores guided by resol/triblock copolymer composite, decoding glycans from complex sample [30]. On the above basis, we applied the resol as a precursor to successfully synthesize a magnetic mesoporous carbon MMC-Fe in this work, and performed N-glycan analysis in conjunction with high-throughput MALDI-TOF MS. In a single synthesis, the yield can reach 0.38 g of MMC-Fe (−0.5 g resol), suitable for large-scale samples. In addition, the MMC-Fe exhibits excellent size exclusion effect (OVA digest:OVA:BSA = 1:300:300), low detection limit (1 ng/µL). Furthermore, we successfully obtained N-glycan information from a total of 57 clinical serum samples including healthy controls, liver cirrhosis, and liver cancer, using MMC-Fe and MALDI-TOF MS. Combining with multiple screening criteria, we identified separately 7 N-glycans with significant differences between health and two disease groups. The selected N-glycans reveal extraordinary performance with area under the curves (AUCs) of 0.948–0.993 for liver disease detection. Thereinto, there are 5 overlapping N-glycans in two sets of 7 N-glycans with significant differences, which show potential for monitoring between liver cirrhosis and AFP-negative liver cancer. Overall, serum N-glycan analysis based on the combination of MMC-Fe and MALDI-TOF MS provides an efficient and accurate solution for detecting liver diseases with a high degree of concealment.
The preparation of MMC-Fe material is described in Fig. S1 (Supporting information), including synthesis of the resol precursor, self-assembly of block-copolymer and carbonization of polymer. The resol precursor was obtained by a base-catalyzed method with phenol and formaldehyde in a molar ratio of 1:2. The resulting resol contains a large number of hydroxyl groups, which can form strong hydrogen bonds with Pluronic F127 template. Based on the solvent evaporation induced self-assembly (EISA) strategy, we introduced Fe(NO3)3·9H2O into a system composed of the template for co-assembly. The evaporation of ethanol at room temperature and the thermopolymerization process at 100 ℃ converted the soluble resols into cross-linked phenolic resin with a network structure [31]. Subsequently, the phenolic resin was directly carbonized to form mesoporous carbon matrix in an N2 atmosphere at 600 ℃. Notably, a large number of γ-Fe2O3 nucleuses are formed within the mesoporous carbon matrix after thermopolymerization and carbonization [32]. This imparts magnetic properties to MMC-Fe material, facilitating magnetic collection and reduction in time cost.
Several characterization techniques were employed to portray the structure and components of MMC-Fe. In the transmission electron microscope (TEM) images (Figs. S2a and b in Supporting information), the dark spots can be assigned to γ-Fe2O3 which are dispersed in the carbon matrix, endowing ordered mesoporous carbon with magnetism. In addition, the typical stripe-like and hexagonal arrangement patterns confirm the ordered mesoscopic structure of MMC-Fe. The mesoporous structure was futher verified by the BET method. A characteristic type-IV curve with hysteresis loop is observed in the nitrogen adsorption/desorption isotherm of MMC-Fe (Fig. S3a in Supporting information), indicating the existence of mesoporous structure. The obvious and steep steps appearing in the P/P0 = 0.45–0.55 range of the adsorption isotherm reflect the high uniformity of mesoporous size [30,32]. The pore size distribution curve in Fig. S3b (Supporting information) illustrates that the pore size of MMC-Fe is approximately 4.0 nm, which makes it possible to capture N-glycans based on size exclusion effect and avoid protein interference. The crystalline structure of MMC-Fe is further analyzed by powder X-ray diffraction (PXRD) technology (Fig. S4a in Supporting information). The six obvious diffraction peaks at 30.4°, 35.7°, 41.9°, 53.6°, 56.9° and 61.2° correspond to the (220), (311), (400), (422), (511) and (440) lattice planes of γ-Fe2O3 (PDF #39-1346), respectively. Additionally, there are two peaks around 26.5° and 44.3° corresponding to (002) and (101) reflections of graphitic carbon (PDF #41-1487) in XRD patterns. The XPS pattern also synergistically confirms the presence of the main elements (C, O, Fe) in the MMC-Fe (Fig. S4b in Supporting information). The characteristic peaks at 1350 cm−1 and 1587 cm−1 in Raman spectroscopy (Fig. S5b in Supporting information) correspond to the D and G bands of carbon materials, respectively. D band is assigned to disordered carbon (sp3), while G band is attributed to a hexagonal carbon (sp2). Raman spectroscopy result indicates that MMC-Fe contains carbon in various states including graphitic carbon, which contributes to the N-glycans enrichment. The Fourier transform infrared spectroscopy (FT-IR) in Fig. S5a (Supporting information) is utilized for structural analysis of MMC-Fe. The strong and wide absorption peak of MMC-Fe in the FT-IR spectrum range of 3000–3670 cm−1 is attributed to the stretching vibration of the -OH groups. The presence of hydroxyl groups enhances the polar interaction between MMC-Fe and glycans [33,34].
In this work, we initially utilized ovalbumin (OVA) digest consisting of glycans and residual proteins as standard sample to assess the enrichment ability of MMC-Fe for N-glycans. In short, the process involves N-glycan enrichment by MMC-Fe in OVA digest, acquisition of MALDI-TOF MS profiling, data processing and analysis based on machine learning model, and identification of key N-glycans related to liver diseases, as illustrated in Fig. 1. For the high-concentration OVA digest, after the entire process described above, a total of 20 glycans were detected, the detailed information of enriched N-glycans is listed in Table S1 (Supporting information). Then we prepared different concentrations (20, 10, 5, and 1 ng/µL) of OVA digest to further test the enrichment ability of MMC-Fe for low-concentration glycans. As shown in Fig. S6 (Supporting information), MMC-Fe is able to capture a certain amount of N-glycans (S/N > 3) even at an OVA concentration of 1 ng/µL. Considering the presence of numerous large-size proteins in biological samples, the unique mesoporous structure of MMC-Fe is quite conducive to selectively capturing small N-glycans while effectively excluding high-abundance proteins. We mixed the standard sample with different mass ratios of OVA and bovine serum albumin (BSA). From Fig. S7 (Supporting information), even in the case of OVA digest:OVA:BSA = 1:300:300, 19 N-glycan signal peaks emerge in the MS spectrum after enrichment by MMC-Fe (Fig. S7c in Supporting information), while no typical N-glycans signal is detected before enrichment (Fig. S7a in Supporting information) due to the protein interference on glycan signals. Moreover, the protein signal peaks only appear in the mixed solution (Fig. S7b in Supporting information) and were not detected in the eluate after enrichment by MMC-Fe (Fig. S7d in Supporting information). The above test indicates the excellent size-exclusion effect and glycan enrichment ability of MMC-Fe.
Drawing from the above investigation on standard sample, we extended our analysis to glycans in 57 serum samples, including 14 healthy controls, 22 liver cirrhosis patients, and 21 liver cancer patients. This study, approved by the Ethics Committee of Shanghai Zhongshan Hospital, Fudan University (No. B2021-837R), adhered to ethical standards, with participants' consent for serum sample collection. The gender distribution of 57 samples in the three cohorts is similar, with a higher proportion of males, as illustrated in Fig. 2a. According to the age ranges of 30–50, 50–70, and 70+, the samples from the three cohorts are divided into three age groups, in which the samples aged 50–70 account for the largest proportion. According to the Pearson Chi-Square test and Mann-Whitney U test, there are no significant differences in gender and age between healthy control group and liver disease group (P > 0.05, Tables S2 and S3 in Supporting information). The treatment procedure of serum samples still follows Fig. 1. Subsequently, the obtained MS data (.txt format) was processed by MALDIquant package on RStudio, and a total of 22 N-glycan characteristic peaks were identified simultaneously in three cohorts (S/N > 3). The typical spectra are shown in Fig. 2b and the detailed information of the N-glycans is displayed in Table S4 (Supporting information). We generated a hierarchical clustering heatmap of these 22 N-glycans to visually illustrate the differences between health and diseases (Fig. S8 in Supporting information). According to all these 22 N-glycans, we first attempted to use orthogonal partial least squares discriminant analysis (OPLS-DA) to distinguish between healthy controls and various liver diseases. The OPLS-DA model is a supervised machine learning method that can separate data changes irrelated to categorical variable Y in the independent variable X, thereby concentrating classification information mainly on one principal component. Furthermore, OPLS-DA utilizes partial least squares regression to construct a relationship model between group category and target expression levels, which can better obtain inter group difference information and achieve sample grouping prediction [35,36]. The graphical representation in Fig. 2c distinctly separates the healthy control group from both liver cirrhosis (R2Y(cum) = 0.726, Q2(cum) = 0.506), and liver cancer (R2Y(cum) = 0.642, Q2(cum) = 0.501). The fitting degree of OPLS-DA is verified by a 200-iteration permutation in Fig. 2d, depicting that all left points are lower than the right points. The intercept R2 and Q2 of the regression line are lower than 0.4 and 0.0, respectively, indicating the high reliability and validity of the OPLS-DA.

In order to determine the most crucial N-glycans associated with liver disease, three important coefficients related to the OPLS-DA model, including variable importance in projection (VIP), P-value, and fold change (FC), are used as filter factors. Thereinto, under the specified criteria of VIP > 1, P < 0.05, and FC < 0.67 or > 1.5, seven N-glycans were respectively picked out for discrimination between healthy control and different liver diseases, namely liver cirrhosis and liver cancer (Tables S5 and S6 in Supporting information). The receiver operating characteristic (ROC) curves were depicted for evaluating the discriminatory performance of these N-glycans. As seen in Figs. 3a and b and Fig. S9 (Supporting information), the AUC value is 0.993 (90.91% sensitivity and 100.00% specificity) for the discrimination between healthy control and liver cirrhosis, and achieves 0.963 (90.48% sensitivity and 92.86% specificity) between healthy control and liver cancer. These demonstrate the high feasibility of selected N-glycans in liver cirrhosis or liver cancer monitoring. Notably, in this study, 71.4% of liver cancer samples (15 cases) tested negative for AFP, which is a commonly used clinical tumor marker for liver cancer. Specifically, AFP levels were found to be less than 20 ng/mL in these samples (Table S7 in Supporting information). In fact, the specificity and sensitivity of the AFP indicator are quite limited, around 45%−65% sensitivity and 78%−89% specificity at critical point of 20 ng/mL [37–39]. From this observation, we employed the selected seven N-glycans to try discriminating AFP-negative liver cancer samples from healthy control samples. Remarkably, AFP-negative liver cancer samples can be successfully separated from healthy controls (0.948 AUC, 80.00% sensitivity and 100.00% specificity) in Figs. S12a and b (Supporting information). These results imply the outstanding advantage of serum N-glycans in liver cancer monitoring.

The heatmaps (Figs. 3c and d) and box plots (Figs. S10 and S11 in Supporting information) were generated to visually observe the expression variances of screend N-glycans across different clinical samples. Of note, there is an overlap of selected N-glycans in the healthy control/liver cirrhosis and healthy control/liver cancer groups. Alterations in the expression levels of the overlapping N-glycans are considerably consistent across both liver disease groups, reflecting the close correlation and commonality between cirrhosis and liver cancer. In specific detail, compared to healthy control groups, the N-glycans represented by m/z 1339.41, m/z 1542.07, m/z 1688.66 and m/z 1850.62 are upregulated, and the N-glycans symbolized by m/z 1905.37 are downregulated in disease groups (Figs. S10 and S11 in Supporting information). Among the five N-glycans overlapped between healthy control/liver cirrhosis and healthy control/liver cancer groups, as well as non-overlapping four N-glycans, the glycans represented by m/z 1339.41, 1542.07, 1850.62, and 2012.68 were identified by Higashi et al., and their alteration trends are consistent with the results obtained in our study. Meanwhile, they identified N-glycan represented by m/z 1850.62 as a potential biomarker for early HCC [40]. It is well known that N-acetylglucosaminyltransferase III (GnT-III) which produces bisecting GlcNAc structures inhibits cancer metastasis, whereas N-acetylglucosaminyltransferase V (GnT-V) which generates multiantennary glycans promotes cancer development [41]. During the development of cirrhosis and liver cancer, Gnt-III and Gnt-V compete for substrates (N-glycans symbolised by m/z 1809.65), which leads to an increase in N-glycans represented by m/z 2012.68 (biantennary glycan) or 2028.66 (triantennary glycan) and a decrease of N-glycan represented by m/z 1809.65 [42]. This is confirmed by the fact that the GlycoCirrhosTest platform established by Callewaert et al. differentiates between healthy and cirrhotic livers mainly by an increase in dichotomous GlcNAc-substituted glycans [43]. In addition, core-fucosylation of N-glycans has been reported to be accomplished mainly by Fuc-TVIII (encoded by FUT8), and overexpression of core-fucosylation is an significant feature of some cancers, including HCC [44,45]. More importantly, the N-glycan glycoform represented by m/z 1809.65 and 2012.68 is precisely core-fucosylated by FUT8, and this glycoform has been shown to be present in AFP-L3 [46]. These disscussion of association between the identified N-glycans and liver diseases may provide support for the application potential of selected serum N-glycans in liver diseases, and indicate the feasibility and credibility of serum N-glycans as biomarkers for liver diseases.
Considering the consistent alteration trend of overlapping five N-glycans in samples from liver cirrhosis and liver cancer, we attempted to distinguish liver cancer from liver cirrhosis based on these five N-glycans. As shown in Fig. 3e and Fig. S9 (Supporting information), the AUC value achieves 0.842 (76.19% sensitivity and 86.36% specificity), suggesting that the five selected N-glycans can make a contribution to progression monitoring between liver cirrhosis and liver cancer. We observed that the AFP values of liver cirrhosis are all below 20 ng/mL same as in healthy controls (Table S7 in Supporting information). Therefore, we conjectured whether it is also possible to separate liver cirrhosis and AFP-negative liver cancer samples through the selected N-glycans at the appropriate AUC. As seen in Figs. S12c and d (Supporting information), AFP-negative liver cancer samples are distinguished from liver cirrhosis samples with an AUC of 0.827 (66.67% sensitivity and 77.27% specificity). In short, the discrimiation between liver cancer (even AFP-negative samples) and liver cirrhosis could be achieved based on the five selected N-glycans, which reveals the great monitoring potential of key N-glycans in liver diseases.
In summary, we successfully synthesized a magnetic mesoporous carbon material based on the EISA strategy. The high yield and low time cost of the prepared MMC-Fe are suitable for large-scale sample treatment, and the appropriate mesoporous structure endow the MMC-Fe with outstanding size-exclusion ability and glycan enrichment performance. The prepared MMC-Fe was applied to N-glycan enrichment analysis of 57 serum samples from healthy controls, liver cirrhosis, and liver cancer. The combination of MALDI-TOF MS profiling and OPLS-DA model validates the excellent discriminative performance of serum N-glycans for healthy controls and liver disease patients. Subsequently, based on a comprehensive evaluation of VIP values, P-values, and FC values, 7 significantly different N-glycans were separately selected from two comparison groups: healthy control/liver cirrhosis and healthy control/liver cancer. The selected N-glycans exhibit remarkable outcome for liver cirrhosis/liver cancer with AUCs of 0.948–0.993, even in AFP-negaitve liver cancer samples. The overlapping five N-glycans in healthy and two disease groups are also confirmed to differentiate liver cirrhosis from liver cancer, as well as for AFP-negative samples, with AUCs of 0.827–0.842. Serum N-glycan analysis based on effective carbon matrix and machine learning models unfolds great potential in the precise monitoring of liver diseases, providing a more efficient and accurate platform for the subdivision and differentiation of more diseases. Additionally, to explore more comprehensive and reliable biomarkers, the introduction of multiple omics such as proteomics and larger sample trials are new approaches, which worth attempting.
The authors declare no conflict of interest.
Yiwen Lin: Data curation, Writing – original draft. Yijie Chen: Investigation. Chunhui Deng: Funding acquisition, Project administration. Nianrong Sun: Writing – review & editing, Funding acquisition, Methodology, Supervision.
This work was financially supported by National Key R&D Program of China (No. 2018YFA0507501) and the National Natural Science Foundation of China (Nos. 22074019, 21425518, 22004017), and Shanghai Sailing Program (No. 20YF1405300).
Supplementary material associated with this article can be found, in the online version, at doi:
F. Bray, J. Ferlay, I. Soerjomataram, et al., CA Cancer J. Clin. 68 (2018) 394–424. doi: 10.3322/caac.21492
R.L. Siegel, K.D. Miller, N.S. Wagle, A. Jemal, CA Cancer J. Clin. 73 (2023) 17–48. doi: 10.3322/caac.21763
A.M. Moon, A.G. Singal, E.B. Tapper, Clin. Gastroenterol. Hepatol. 18 (2020) 2650–2666. doi: 10.1016/j.cgh.2019.07.060
M. Senzolo, G. Garcia-Tsao, J.C. García-Pagán, J. Hepatol. 75 (2021) 442–453. doi: 10.1016/j.jhep.2021.04.029
R.M. Feng, Y.N. Zong, S.M. Cao, R.H. Xu, Cancer Commun. 39 (2019) 22.
J. Fu, H.Y. Wang, Cancer Lett. 412 (2018) 283–288. doi: 10.1016/j.canlet.2017.10.008
A. Forner, J.M. Llovet, J. Bruix, Lancet 379 (2012) 1245–1255. doi: 10.1016/S0140-6736(11)61347-0
J.M. Llovet, A. Burroughs, J. Bruix, Lancet 362 (2003) 1907–1917. doi: 10.1016/S0140-6736(03)14964-1
X.T. Zhang, H.B. El-Serag, A.P. Thrift, Cancer Causes Control 32 (2021) 317–325. doi: 10.1007/s10552-020-01386-x
S.S. Sun, Y.W. Hu, M.H. Ao, et al., Clin. Proteomics 16 (2019) 35. doi: 10.1186/s12014-019-9254-0
J. Ma, D.H. Wang, J. She, et al., New Phytol. 212 (2016) 282–296. doi: 10.1111/nph.14014
D. Thomas, A.K. Rathinavel, P. Radhakrishnan, Biochim. Biophys. Acta Rev. Cancer 1875 (2021) 188464. doi: 10.1016/j.bbcan.2020.188464
K. Ohtsubo, J.D. Marth, Cell 126 (2006) 855–867. doi: 10.1016/j.cell.2006.08.019
A. Kobata, J. Amano, Immunol. Cell Biol. 83 (2005) 429–439. doi: 10.1111/j.1440-1711.2005.01351.x
H. Narimatsu, Expert Rev. Proteomics 12 (2015) 683–693. doi: 10.1586/14789450.2015.1084874
Y. Sato, K. Nakata, Y. Kato, et al., N. Engl. J. Med. 328 (1993) 1802–1806. doi: 10.1056/NEJM199306243282502
M.N. Christiansen, J. Chik, L. Lee, et al., Proteomics 14 (2014) 525–546. doi: 10.1002/pmic.201300387
K. Noda, E. Miyoshi, N. Uozumi, et al., Hepatology 28 (1998) 944–952. doi: 10.1002/hep.510280408
K. Taketa, Y. Endo, C. Sekiya, et al., Cancer Res. 53 (1993) 5419–5423.
M. Force, G. Park, D. Chalikonda, et al., Viruses 14 (2022) 775. doi: 10.3390/v14040775
X.Y. Yi, S. Yu, Y.X. Bao, Clin. Chim. Acta 425 (2013) 212–220. doi: 10.1016/j.cca.2013.08.005
H. Hanif, M.J. Ali, A.T. Susheela, et al., World J. Gastroenterol. 28 (2022) 216–229. doi: 10.3748/wjg.v28.i2.216
L. Huang, J.J. Wan, X. Wei, et al., Nat. Commun. 8 (2017) 220. doi: 10.1038/s41467-017-00220-4
D.J. Harvey, Mass Spectrom. Rev. 42 (2023) 1984–2206. doi: 10.1002/mas.21806
H.Y.H. Zhang, F.Y. Shi, Y.H. Yan, C.H. Deng, N.R. Sun, Adv. Healthc. Mater. 12 (2023) e2301136.
L.C. Lazari, F.R. Ghilardi, L. Rosa-Fernandes, et al., Life Sci. Alliance 4 (2021) e202000946.
N.R. Sun, J.Z. Yao, C.H. Deng, Talanta 148 (2016) 439–443. doi: 10.1016/j.talanta.2015.11.011
N.R. Sun, J.Z. Yao, J.J. Wang, Y. Li, C.H. Deng, RSC Adv. 6 (2016) 34434–34438. doi: 10.1039/C6RA01434H
Y.L. Wu, Y.J. Chen, H.L. Chen, et al., Chem. Commun. 57 (2021) 11362–11365. doi: 10.1039/D1CC04699C
Y.J. Chen, Y.L. Wu, J.M. Li, C.H. Deng, N. Sun, Mikrochim. Acta 190 (2023) 319. doi: 10.1007/s00604-023-05885-x
Y. Meng, D. Gu, F.Q. Zhang, et al., Chem. Mater. 18 (2006) 4447–4464. doi: 10.1021/cm060921u
Y.P. Zhai, Y.Q. Dou, X.X. Liu, B. Tu, D.Y. Zhao, J. Mater. Chem. 19 (2009) 3292–3300. doi: 10.1039/b821945a
J.Q. Fan, A. Kondo, I. Kato, Y.C. Lee, Anal. Biochem. 219 (1994) 224–229. doi: 10.1006/abio.1994.1261
H.Q. Qin, L. Zhao, R.B. Li, R.A. Wu, H.F. Zou, Anal. Chem. 83 (2011) 7721–7728. doi: 10.1021/ac201198q
M. Bylesjö, M. Rantalainen, O. Cloarec, et al., J. Chemom. 20 (2006) 341–351. doi: 10.1002/cem.1006
J. Trygg, S. Wold, J. Chemom. 16 (2002) 119–128. doi: 10.1002/cem.695
X. Ye, C.Y. Li, X.Y. Zu, et al., Hepatology 69 (2019) 2489–2501. doi: 10.1002/hep.30519
A. Forner, J. Bruix, Lancet Oncol. 13 (2012) 750–751. doi: 10.1016/S1470-2045(12)70271-1
F. Trevisani, P.E. D’Intino, A.M. Morselli-Labate, et al., J. Hepatol. 34 (2001) 570–575. doi: 10.1016/S0168-8278(00)00053-2
M. Higashi, T. Yoshimura, N. Usui, et al., Int. J. Mol. Sci. 21 (2020) 8913. doi: 10.3390/ijms21238913
N. Taniguchi, Y. Ohkawa, K. Maeda, et al., Mol. Aspects Med. 79 (2021) 100905. doi: 10.1016/j.mam.2020.100905
X.E. Liu, L. Desmyter, C.F. Gao, et al., Hepatology 46 (2007) 1426–1435. doi: 10.1002/hep.21855
N. Callewaert, H. Van Vlierberghe, A. Van Hecke, et al., Nat. Med. 10 (2004) 429–434. doi: 10.1038/nm1006
S.S. Pinho, C.A. Reis, Nat. Rev. Cancer 15 (2015) 540–555. doi: 10.1038/nrc3982
W.L. Hutchinson, M.Q. Du, P.J. Johnson, R. Williams, Hepatology 13 (1991) 683–688. doi: 10.1002/hep.1840130412
T. Nakagawa, E. Miyoshi, T. Yakushijin, et al., J. Proteome Res. 7 (2008) 2222–2233. doi: 10.1021/pr700841q

Figure 1 Schematic overview of serum N-glycans enrichment by MMC-Fe and MALDI-TOF MS profiling analysis.

Figure 2 (a) Sample scale, gender distribution, and age distribution of three cohorts including healthy control, liver cirrhosis and liver cancer. (b) The typical MS spectra of N-glycans from three sets of serum digests using MMC-Fe. (c) OPLS-DA score plots of serum N-glycans and (d) corresponding 200 permutations for discrimination between healthy control and liver cirrhosis/liver cancer.

Figure 3 The receiver operating characteristic (ROC) curve based on the selected N-glycans in (a) healthy control/liver cirrhosis, (b) healthy control/liver cancer and (c) liver cirrhosis and liver cancer. Heatmap based on the selected N-glycans in (d) healthy control/liver cirrhosis and (e) healthy control/liver cancer.

 扫一扫看文章
扫一扫看文章

扫一扫关注我们
 DownLoad:
DownLoad:
 下载:
下载:
 下载:
下载: