Table 1.
Ablation experiments of BiCINet for USPTO_50 K dataset.
Citation:
Xi Xue, Kai Chen, Hanyu Sun, Xiangying Liu, Xue Liu, Shize Li, Jingjie Yan, Yu Peng, Mohammad S. Mubarak, Ahmed Al-Harrasi, Hai-Yu Hu, Yafeng Deng, Xiandao Pan, Xiaojian Wang. Bidirectional Chemical Intelligent Net: A unified deep learning–based framework for predicting chemical reaction[J]. Chinese Chemical Letters,
2025, 36(11): 110968.
doi:
10.1016/j.cclet.2025.110968

Bidirectional Chemical Intelligent Net: A unified deep learning–based framework for predicting chemical reaction
English
Bidirectional Chemical Intelligent Net: A unified deep learning–based framework for predicting chemical reaction
Abstract:
Chemical reactions, which transform one set of substances to another, drive research in chemistry and biology. Recently, computer-aided chemical reaction prediction has spurred rapidly growing interest, and various deep learning–based algorithms have been proposed. However, current efforts primarily focus on developing models that support specific applications, with less emphasis on building unified frameworks that predict chemical reactions. Here, we developed Bidirectional Chemical Intelligent Net (BiCINet), a prediction framework based on Bidirectional and Auto-Regressive Transformers (BARTs), for predicting chemical reactions in various tasks, including the bidirectional prediction of organic synthesis and enzyme-mediated chemical reactions. This versatile framework was trained using general chemical reactions and achieved top-1 forward and backward accuracies of 80.7% and 48.6%, respectively, for the public benchmark dataset USPTO_50K. By multitask transfer learning and integrating various task prompts into the model, BiCINet enables retrosynthetic planning and metabolic prediction for small molecules, as well as retrosynthetic analysis and enzyme-catalyzed product prediction for natural products. These results demonstrate the superiority of our multifunctional framework for comprehensively understanding chemical reactions.
-
Key words:
- Machine learning
- / Deep learning
- / Chemical reaction prediction
- / Retrosynthesis
- / Metabolism
- / Biocatalytic reactions
-
Chemical reactions transform one set of substances to another by breaking and forming bonds between atoms, which is a central part of several fields, including chemistry and biology [1,2]. Predicting how molecules react involves both organic synthesis and enzyme-mediated chemical reactions [3]. The former encompasses forward and backward reaction prediction, while the latter includes enzymatic catalysis and metabolism. The prediction of reactants and products is challenging, even for experienced chemists, because of the huge search space and incomplete understanding of reaction mechanisms [4]. In recent years, the rapid development of artificial intelligence (AI), particularly deep-learning methods, has enabled the use of data-driven deep-learning methods to address the challenge of predicting chemical reactions [5–10].
The prediction of products synthesized from reactants and reagents and identification of starting materials from target molecules are fundamental to organic synthesis [11]. Substantial effort has been dedicated to designing AI strategies for organic synthesis [12–19], encompassing both template-based and template-free models [10]. Although template-based methods are interpretable, their generalizability is limited, which hinders predictions involving unknown template-uncovered structures. Template-free methods, usually divided into sequence- and graph-based, directly transform products into potential reactants [18]. In this context, Liu et al. [20] presented a data-driven model with an encoder–decoder architecture consisting of long short-term memory (LSTM) cells, that approaches retrosynthetic reaction prediction as a sequence-to-sequence mapping problem. Subsequently, the transformer-based method for retrosynthesis was proposed by Karpov et al. [15] and achieved better performance. To solve the grammatically invalid output problem in sequence-to-sequence mapping, Zheng and coworkers [12] added a grammar corrector to the traditional Transformer called SCROP. In addition, numerous graph-based retrosynthetic approaches using graph neural networks (GNNs) have been developed. In this regard, Shi and colleagues [21] proposed a template-free graph-to-graph (G2 G) approach by transforming a target molecular graph into a set of reactant molecular graphs. Tu et al. [22] introduced Graph2SMILES, a graph-to-sequence architecture, using a sequential graph encoder and a transformer decoder to convert molecular graphs to SMILES outputs, ensuring permutation invariance without requiring input-side augmentation. To address the challenge of explaining deep-learning methods, Wang et al. [9] proposed RetroExplainer, which formulates the retrosynthesis task as a molecular assembly process, enabling quantitative interpretable retrosynthesis predictions. Some template-free model architectures and techniques used in retrosynthesis, such as those developed by Tetko et al. [23] and Zhong et al. [24], have also been directly applied in the forward direction prediction. Molecular Transformer [25], an attention-based machine translation model proposed by Lee et al. can address both reaction prediction and retrosynthesis by learning from the same dataset.
Deep learning is also employed in predicting enzyme-mediated chemical reactions [26,27]. Biocatalysis, the use of enzymes for organic synthesis, allows for simplified, more economical, and selective synthetic routes that are inaccessible using conventional reagents [28]. Deep learning models that utilize biocatalytic reactions are still in the early stages of development. Kreutter et al. [29] combined the reaction SMILES language with thousands of human language tokens describing enzymes and trained the molecular transformer for predicting enzymatic reactions. Similarly, Probst et al. [30] extended the data-driven forward reaction and Molecular Transformer architecture–based retrosynthetic pathway prediction models to biocatalysis. Another area of enzyme-catalyzed reaction prediction focuses on drug metabolism [31]. Metabolic processes involve forward chemical reactions mediated by enzymes, such as the cytochrome P450 (CYP450) family [32]. Along this line, multiple efforts have been made to develop deep learning models for predicting drug metabolism to aid the integration of metabolic studies in drug development [33–35]. Wang et al. [36] established a model to predict the main metabolites of drugs by combining a metabolic reaction template and deep learning. Litsa et al. [37] presented a rule-free, end-to-end learning–based method for predicting possible metabolites of small molecules, including drugs. Although current research in predicting chemical reactions primarily focuses on developing models that support specific applications, with less emphasis on building unified frameworks, the core of all chemical reaction predictions is the breakage and formation of chemical bonds between atoms. In this study, using bidirectional and autoregressive transformers (BART) [38], we set training tasks applicable for learning chemical reaction rules and built a Bidirectional Chemical Intelligent Net (BiCINet) unified framework for predicting bidirectional chemical reactions. The model's performance was evaluated using the public benchmark dataset USPTO_50 K, achieving top-1-ranked forward and backward accuracies of 80.7% and 48.6%, respectively. This framework was applied to different datasets, realizing the function of predicting bidirectional organic synthesis, enzyme-catalyzed reactions and drug metabolism. The attention weights of different reaction classes were discussed to enhance the understanding of our model. Furthermore, the performance of our models was evaluated in multiple scenarios to verify the practical applicability of the models in predicting chemical reactions. The integrated models achieve remarkable performance in various chemical predictive tasks, including enabling efficient retrosynthetic planning and metabolic predictions for small molecules, as well as comprehensive retrosynthetic analysis and accurate enzyme-catalyzed product predictions for natural products. These results highlight the superiority of our versatile framework, demonstrating its ability to comprehensively analyze chemical reactions. For ease of use, the model has been integrated on a server accessible at
http://hpc.cams.cn:22469/ . The code repository for BiCINet is publicly available athttps://github.com/WJmodels/BiCINet .The initial data used to optimize and evaluate the model were sourced from the public dataset USPTO_50 K, which includes 50, 016 reactions across 10 distinct reaction types. Another public dataset, USPTO_MIT, containing 479, 035 reaction data entries, was utilized for evaluating the model. The USPTO_FULL dataset, comprising 1808, 938 reactions, was processed through deduplication and canonicalization, resulting in 1048, 576 unique reactions used for pretraining the model. Subsequently, the model was fine-tuned for downstream prediction tasks. The dataset was randomly split into training/validation/test sets (80%/10%/10%, respectively) for training and evaluating the model.
The metabolism dataset used for fine-tuning the pretrained model was sourced from DrugBank (version 5.1.12). After reactions generating multiple products were split into individual records, each containing a single substrate and product, 3417 valid records remained after duplicates and invalid SMILES representations were removed. Simple ions or gases, deemed as being irrelevant for studying metabolic reactions, were excluded, leaving 3380 valid reactions. This dataset was randomly divided into training, validation, and test sets (90%/5%/5%, respectively). In addition, 639 prodrugs and their active drugs were collected from smProdrugs [39] and the literature. Considering the duplication between prodrug activation processes in vivo and metabolism, a combined dataset comprising prodrug and metabolism data was deduplicated to yield 3705 entries used for fine-tuning the model.
The enzyme-catalyzed reaction dataset used for fine-tuning the pretrained model was sourced from ECREACT, developed by Probst et al. [30], containing 62, 222 reactions. For enzyme coding, four strings were employed to define different classification levels. For example, "EC2.7.8.41" is expressed as "E_1.2, E_2.7, E_3.8, E_4.41, " where the first number represents the hierarchical relationship between major categories and subcategories, and the subsequent numbers represent types of enzymatic reactions classified according to the International Classification of Enzymes. These datasets were randomly split into training/validation/test sets (80%/10%/10%, respectively).
All the datasets were divided into reactants and products based on " > > ", with multiple reactant molecules separated by ".". The SMILES was standardized using RDKit (version 2021.03.1).
The BART backbone comprised six encoder layers with 12 attention heads and six decoder layers with 12 attention heads and 768 hidden dimensional units. The BiCINet encoder encodes product/reactant SMILES to a hidden state and then the BiCINet decoder generates one token at a time, conditioned based on the preceding tokens and the encoded hidden state. Finally, the prediction token gathers and outputs complete reactant/product SMILES.
Two metrics, exact match and MaxFrag accuracies, were used for evaluating the model. The exact match accuracy was computed by matching the canonical SMILES of the predicted reactants to the ground truth in the dataset. To overcome the prediction limitation due to unclear reagent reactions in the dataset, the MaxFrag accuracy was used to calculate the exact match of only the largest fragment.
Four generalized training tasks were introduced as follows to reduce the overfitting risk and improve the model's generalization:
(1) Backward prediction, in which the product and reactant SMILES are input and output, respectively. This strategy is designed to enable the model to generate reactants for input product.
(2) Forward prediction, the inverse of task (1), where reactant and product SMILES are input and output, respectively.
(3) Masked language–modeling product prediction, in which 15% randomly masked and complete product SMILES are input and output, respectively.
(4) Canonical SMILES prediction, in which reactants' "random-rooted SMILES strings" and unique "canonical SMILES" are input and output, respectively.
These four tasks are alternately performed to enhance the model's ability to effectively predict chemical reactions during training. The first two tasks are designed for predicting bidirectional chemical reactions, whereas the last two tasks focus on teaching the model the grammar rules of molecular SMILES notation.
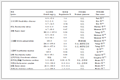
To verify the impact of our strategy on the model, ablation experiments were conducted on the model's tasks (Table 1). In backward prediction, the masking strategy increased the model's accuracy by 1.4%. Notably, the alternation of tasks (1) and (2) enabled the model to simultaneously learn forward and backward predictions, especially in forward prediction, for which the accuracy improved by 4.6%. During model optimization, the beam size (the beam search algorithm parameter that determines the number of the best partial solutions to evaluate) was set at 1, and the top-1 accuracy was used as the evaluation index (Tables S1 and S2 in Supporting information).
Table 1
 DownLoad:
CSV
DownLoad:
CSV
Mode Class Batch size Task_percenta Flag_dualb Learning_rate Top1_accuracy (%) Bc FALSE 32 1.0 TRUE 5.00E−05 40.8 B FALSE 32 0.5 TRUE 5.00E−05 42.1 B TRUE 64 1.0 TRUE 1.00E−04 51.5 B TRUE 64 0.5 TRUE 1.00E−04 54.0 Fd FALSE 64 1.0 FALSE 1.00E−04 76.1 F FALSE 64 1.0 TRUE 1.00E−04 80.7 a "Task_percent" = 1.0 implies no masking. Task_percent = 0.5 implies a 50% probability for masking products.
b "Flag_dual" = True implies bidirectional training will be performed on both reactants and products.
c B means backward.
d F means forward.The most accurate parameters were selected for evaluating the model's performance. As summarized in Table 2, the top-1 and top-10 accuracies of the backward model and mode are 48.6% and 73.9%, respectively. The evaluation results of the forward mode are also shown in Table 2, and the top-1 exact match accuracy reaches 80.7%. The accuracy of the forward model consistently exceeds that of the backward model, as observed in the results of most prediction models, suggesting that backward prediction involves inferring possible precursors from the target molecule, which requires the model to comprehensively learn more complex rules. The MaxFrag accuracy of our model substantially outperforms the exact-match accuracy by 5.4% on average, which is meaningful in practical applications. For experts, the prediction of the main reactants provides guidance for conducting experiments.
Table 2
Table 2. Performance of BiCINet framework for the USPTO_50 K dataset.DownLoad:
CSV
Top-K 50K_Backward 50K_Forward Accuracy (%) Max_accuracy (%) Accuracy (%) Max_accuracy (%) 1 48.6 52.9 80.7 86.2 3 64.9 70.1 88.3 92.6 5 69.4 75.5 89.7 94.0 10 73.9 81.6 91.1 95.2 50 82.1 88.3 93.7 96.3 100 85.9 88.8 95.1 96.4 To thoroughly evaluate the model's performance, chemical reaction class information was incorporated into the model, and the model's accuracy substantially increased (Table 3). The top-1 accuracies of the reverse and forward models reached 62.2% and 82.8%, respectively. It is worth noting that provided with a reaction-type hint, the forward model achieves a top-10 MaxFrag accuracy of 97.5%. Clearly, with added categories, the percentage increase in the accuracy is substantially higher for the forward than the backward model, indicating that categories can more effectively assist in retrosynthetic analysis. Subsequently, we compared our model with others. Compared with existing retrosynthesis prediction models, our model shows a comparable or even better performance. As shown in Table S3 (Supporting information), with prior reaction class information, the top-1 backward prediction accuracy of our model is much higher than that of the transformer-based model proposed by Lin et al. [16], and higher than those of MEGAN [18] and SCROP [12]. When reaction classes are not provided, the top-1 accuracy of our model is still higher than the above three methods. Although our model exhibits a lower top-1 accuracy comparable to those of GTA [40] and Graph2SMILES, it outperforms and surpasses the top-5 and top-10 accuracies of GTA and Graph2SMILES, respectively. In addition, the model's performance was evaluated using the USPTO_MIT dataset (Table S4 in Supporting information); the round-trip accuracy was incorporated to assess the model's performance (Table S5 in Supporting information). Notably, the round-trip accuracies are substantially lower than those of the first two evaluation indicators. The forward model is more accurate than the backward model and is used to evaluate the inverse model. Consequently, during the round-trip performance evaluation, the accuracy of the backward model exceeds that of the forward model and vice versa. The top-10 round-trip accuracy of the backward mode was 93.6%, indicating that in the backward mode, even if the predicted reactants were not the ground truth, they may still be feasible in practical applications.
Table 3
Table 3. Performance of BiCINet framework for the USPTO_50K_class dataset.DownLoad:
CSV
Top-K 50K_Backward 50K_Forward Accuracy (%) Max_accuracy (%) Accuracy (%) Max_accuracy (%) 1 62.2 66.6 82.8 90.1 3 77.0 81.6 87.8 95.8 5 80.3 85.9 88.7 96.7 10 83.0 89.8 89.6 97.5 50 90.0 93.3 91.2 98.3 100 93.1 93.4 91.6 98.3 Next, the model's performance was evaluated across different reaction types. The prediction accuracies of different reaction classes are shown in Fig. 1. Interestingly, the model's predictions were more accurate in response to heteroatom alkylation and arylation reactions in both the forward and backward modes, suggesting that these reactions involve relatively minor changes between the reactants and products. However, for reaction classes, such as heterocycle formation, which involve large skeletal changes, the model's prediction accuracy was low. Furthermore, the similarity between the predicted result and ground truth was evaluated (Fig. S1 in Supporting information); hence, both the molecular similarity and reaction class complexity affect the model's prediction accuracy.
Figure 1
 Figure 1. The model's prediction accuracies in the forward and backward modes for different reaction classes.
Figure 1. The model's prediction accuracies in the forward and backward modes for different reaction classes.Because the interpretability of models is crucial for understanding how deep-learning models study chemical transformations, we unboxed the forward and backward prediction model to elucidate its exploitation of chemical reaction information (Fig. S2 in Supporting information). For the forward prediction model, the effects of the attention weights on acylation and related reactions are shown in Fig. 2. The connection between the reactants and products is modeled via self-attention and multihead attention in the encoder/decoder layers. Because the probability distribution over all the prediction candidates is computed based on the current translation state, summarized by the last multihead attention and output layer, our analysis focused on this last part of the decoder by considering only its attention weights. These results indicate that the model relies on the connections between reactants to predict the product. When only one reactant is present, the model's attention is dispersed around the heteroatom, which aligns with reaction mechanism principles, as heteroatom functional groups exhibit higher reactivities during reactions.
Figure 2
 Figure 2. Attention weights of forward and backward organic synthesis reactions.
Figure 2. Attention weights of forward and backward organic synthesis reactions.To verify the proposed model's practical application potential in predicting syntheses, we extended our one-step USPTO_50K-trained model to a full-pathway design by sequentially predicting organic reactions for target compounds, including the nonsteroidal anti-inflammatory drug indomethacin, the long-acting beta-adrenoceptor agonist bambuterol, and the kinase inhibitor osimertinib, used by other retrosynthetic programs. As shown in Scheme 1a, the prediction results for indomethacin are almost completely consistent with those previously published literature. The only difference is in the selection of the carboxyl-protecting group, while the isopropyl group is shown in the literature. In the multistep retrosynthetic analysis of bambuterol, the prediction results of the model are completely consistent with those in the literature in the first two steps (Scheme 1b). However, according to the literature, the first two steps are nucleophilic substitution and subsequent bromination reactions, while the proposed model predicted an opposite order for these steps. Notably, although the model predicted that the nucleophilic substitution is decomposed into two steps, experimentally, two hydroxyl groups can simultaneously undergo nucleophilic substitution. The forward and backward predictions were both evaluated for osimertinib. Surprisingly, within the top 10, our model infers complete synthetic routes in both the forward and backward predictions (Schemes 1c and d).
Scheme 1
 Scheme 1. Multistep retrosyntheses of (a) indomethacin and (b) bambuterol and (c) multistep retrosynthesis and (d) forward prediction of osimertinib.
Scheme 1. Multistep retrosyntheses of (a) indomethacin and (b) bambuterol and (c) multistep retrosynthesis and (d) forward prediction of osimertinib.Metabolite prediction is closely related to chemical reaction prediction, which could be regarded as the forward prediction. We used a metabolism dataset to fine-tune the USPTO-pretrained forward model for predicting metabolites, achieving top-10 accuracy as 52.9% for the test set. To further verify the practical applicability of the proposed model, we randomly selected two small-molecule drugs from the DrugBank database, including a typical antipsychotic (aripiprazole) and a beta-blocker (atenolol). As shown in Scheme S1 (Supporting information), the proposed model predicts the top-2 phase Ⅰ metabolites of aripiprazole and the glucuronidation metabolites of atenolol, clearly indicating that our model predicts both phase Ⅰ and Ⅱ metabolisms equally accurately. Furthermore, the model's accuracy was evaluated for predicting the metabolism from prodrug to drug molecules. The model accurately predicted the active drug sulfasalazine, which is used to treat rheumatoid arthritis, and the active form of the reactive oxygen species of the responsive prodrug doxorubicin.
Additionally, to clarify syntactic rules in chemical reactions, we screened the reactions of metabolism-resembling classes from the USPTO dataset for pretraining the proposed model. The results in Table S6 (Supporting information) indicate that the model exhibited inferior performance for datasets possessing similar categories, suggesting that during training, the model predominantly learns the data distribution rather than the underlying rules of chemical transformations.
The dataset compiled from public databases by Probst et al. was used to construct the enzyme-catalyzed reaction model. The top-1, −5, and −10 accuracies of various model categories for the test dataset were 54.5%, 67.4%, and 72.4%, surpassing those that Probst et al. reported for the forward prediction of the enzymatic catalysis, which were 49.6%, 63.5%, and 68.8%, respectively. These results demonstrate that our training strategy is effective and improves the model's prediction accuracy. In addition, the model's accuracy was evaluated for predicting a different enzyme level (Fig. 3). The model's accuracy for predicting reactions catalyzed by translocases and oxidoreductases was superior to that for predicting reactions catalyzed by lyases (Fig. S3 in Supporting information) because these data comprised most of the training set.
Figure 3
 Figure 3. Heatmap showing prediction accuracy for different enzyme-catalyzed products.
Figure 3. Heatmap showing prediction accuracy for different enzyme-catalyzed products.Subsequently, we used a dataset comprising the total syntheses of natural products collected from the literature to fine-tune the model and evaluate its effectiveness in planning the retrosynthetic route for the key intermediate in the total synthesis of the natural product (−)-aplaminal. As shown in Scheme S2 (Supporting information), our model inferred six steps that align with the results reported in the literature. In the six reaction steps of the synthetic pathway, our method succeeds within the top-10 prediction for all the steps except step 4 predicted at the top 33, which directly demonstrates the superiority of our method. Our model accurately predicted the first three steps, including reduction, methylation, and azidation. The subsequent steps are the deprotection and cyclization reactions, and the last step is the removal of the protecting group. These results further demonstrate the excellent potential of our model for practical application to multistep retrosynthesis.
Several common small-molecule drugs were randomly selected from the DrugBank database to predict their single-step synthesis methods and metabolites, results are shown in Scheme 2, mefenamic acid is a nonsteroidal anti-inflammatory drug (NSAID) used to treat mild to moderate pain. Notably, in mefenamic acid, the benzene ring possesses two methyl groups that are both easily metabolized by the body, which somewhat interferes with the model's prediction accuracy. The model accurately predicted the top-1 and top-6 mefenamic acid reactants and metabolites, respectively. Caffeine is the most widely used central nervous system stimulant. The model accurately predicted the top-1 reactants but failed to correctly predict the top-10 metabolites, suggesting that the caffeine structure contains multiple nitrogen atoms, which interfere with the model's prediction accuracy. The SMILES syntax limitations hinder the model's ability to correctly predict changed token positions. For rheumatoid arthritis and antianxiety drugs tolmetin and lorazepam, respectively, the model accurately predicted the top-1-ranked reactants and metabolites. In the body, tolmetin and lorazepam are both metabolized as glucuronic acid, indicating that, except for caffeine, the model accurately predicted the top-10 drug metabolites. Our model correctly predicted all the top-1 single-step reactions in various categories, such as nucleophilic substitution, hydrolysis, and acylation, and accurately predicted drug molecules in both directions.
Scheme 2
 Scheme 2. Single-step retrosynthetic analysis and metabolic prediction of small-molecule drugs.
Scheme 2. Single-step retrosynthetic analysis and metabolic prediction of small-molecule drugs.Furthermore, the potential of our model for generating reactant and natural-product candidates was examined for enzymatic catalysis. Target compounds, including glutamate receptor agonists xanthurenic acid, estrogen estradiol, the natural retinoid vitamin A (VA) all-trans-retinal, and the coniferyl aldehyde reduction product coniferyl alcohol, were selected. None of these input structures (products or intermediates) was present in our training set. For xanthurenic acid (Scheme 3a), the reactants of demethylation were accurately predicted at top-6. For methyltransferase catalysis, the enzymatic catalysis product was accurately predicted at top-1. Notably, organic and enzyme-catalyzed syntheses involve changes in carbon–oxygen bonds, which further illustrate the universality of chemical reactions. As shown in Scheme 3b, although the estradiol structure contains multiple chiral centers, our model correctly predicted the top-6 and top-1 estradiol reactants and monooxygenase catalytic products, respectively. The prediction of a top-1 natural retinoid is shown in Scheme 3c. The reactants and enzyme-catalyzed products have the same structure, indicating that in the structure, the aldehyde group is highly reactive under all conditions. Scheme 3d shows the top-1 accurate predictions of the retrosynthesis planning and dehydrogenase catalysis of coniferyl alcohol, which indicates the practical application potential of our model. Therefore, the proposed model correctly predicted top-10-ranked reactions, such as functional group conversion in natural-product molecules.
Scheme 3
 Scheme 3. Analysis of single-step retrosynthesis and prediction of enzyme-catalyzed reactions of natural products.
Scheme 3. Analysis of single-step retrosynthesis and prediction of enzyme-catalyzed reactions of natural products.BiCINet has been integrated into a web server for convenient chemical reaction prediction. Users can customize prediction tasks, such as chemical reactions, retrosynthesis, drug molecule metabolism, and enzymatic catalysis of molecules. The server accepts three input methods: drawing chemical structures, entering SMILES strings, and uploading files. Meanwhile, the number of candidate prediction outputs can be selected. The website address is
http://hpc.cams.cn:22469/ .We developed a unified bidirectional model named BiCINet for predicting chemical reactions in various scenarios, including synthesis, retrosynthesis, metabolism, and enzymatic catalysis. Compared with rule-based models, BiCINet is a fully data-driven model that does not require high-quality extraction of reaction templates. The model's top-1 exact-match forward and backward prediction accuracies were 80.7% and 48.6%, respectively, for the USPTO_50 K dataset. Comprehensive evaluations of the benchmark dataset demonstrate that compared with models in previous studies, our versatile model achieves equivalent prediction accuracies. In addition, the interpretability of different reaction classes was discussed to clarify our model. For downstream datasets, domain adaptation was achieved through multitask transfer learning by integrating various task prompts into the model. The case study revealed that the integrated models accurately predicted the metabolism and retrosynthetic analysis of small molecules and enabled synthetic route planning for natural products, which demonstrated the superiority of our unified versatile model for accommodating comprehensive chemistry reaction settings.
The model's prediction results are imperfect because of the limited data availability and inherent limitations of the algorithm. These failures likely stem from the inherent complexity of the reaction mechanisms, limited representation in the training data, or insufficient capture of key features by the model. First, SMILES is not robust in describing subtle changes in molecular structures, and model-generated SMILES strings require extremely strict grammatical restrictions to be decoded into valid molecules, which increases the cost of model learning. In addition, molecules rarely possess only one reactive functional group, and each reactive functional group exhibits distinct behaviors under diverse reaction conditions. Consequently, model-learned chemical reactions may not always be applicable because of the influence of specific groups, leading to deviations in the prediction accuracy. Therefore, a transfer-learning strategy must be adopted for specific data types, as certain reaction prediction types have certain similarities in the chemical space distribution. Moreover, although our assessment of the model's predictive outcomes primarily relies on experimental data obtained from the literature, some plausible model predictions remain unreported in existing studies and call for a more comprehensive and reasoned evaluation approach. These challenges will prompt us to soon design more accurate models for predicting chemical reactions, leveraging larger and more diverse chemical knowledge databases for model training to advance our approach.
Declaration of competing interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
CRediT authorship contribution statement
Xi Xue: Writing – original draft, Project administration. Kai Chen: Writing – original draft, Project administration. Hanyu Sun: Writing – original draft, Formal analysis. Xiangying Liu: Formal analysis, Data curation. Xue Liu: Data curation, Conceptualization. Shize Li: Data curation. Jingjie Yan: Data curation. Yu Peng: Data curation. Mohammad S. Mubarak: Writing – review & editing. Ahmed Al-Harrasi: Writing – review & editing. Hai-Yu Hu: Writing – review & editing. Yafeng Deng: Writing – review & editing. Xiandao Pan: Writing – review & editing. Xiaojian Wang: Writing – review & editing.
Acknowledgments
This work was financially supported by the National Natural Science Foundation of China (NSFC, No. 82073692) and CAMS Innovation Fund for Medical Sciences (CIFMS, No. 2021-I2M-1-028). The computing resources were supported by the Biomedical High Performance Computing Platform, Chinese Academy of Medical Sciences.
Supplementary materials
Supplementary material associated with this article can be found, in the online version, at doi:
10.1016/j.cclet.2025.110968 .
-
-
[1]
Z. Tu, T. Stuyver, C.W. Coley, Chem. Sci. 14 (2023) 226–244. doi: 10.1039/d2sc05089g
-
[2]
M. Meuwly, Chem. Rev. 121 (2021) 10218–10239. doi: 10.1021/acs.chemrev.1c00033
-
[3]
Testa, B., Pedretti, A., Vistoli, G. Drug Discov. Today 17 (2012) 549–560. doi: 10.1016/j.drudis.2012.01.017
-
[4]
W. Zhong, Z. Yang, C.Y.C. Chen, Nat. Commun. 14 (2023) 3009. doi: 10.1038/s41467-023-38851-5
-
[5]
S. Chen, Y. Jung, Nat. Mach. Intell. 4 (2022) 772–780. doi: 10.1038/s42256-022-00526-z
-
[6]
D. Fooshee, A. Mood, E. Gutman, et al., Mol. Syst. Des. Eng. 3 (2018) 442–452. doi: 10.1039/c7me00107j
-
[7]
B. Li, S. Su, C. Zhu, et al., J. Cheminform. 15 (2023) 72. doi: 10.54097/ajmss.v2i3.8719
-
[8]
M.H.S. Segler, M.P. Waller, Chem. Eur. J. 23 (2017) 5966–5971. doi: 10.1002/chem.201605499
-
[9]
Y. Wang, C. Pang, Y. Wang, et al., Nat. Commun. 14 (2023) 6155. doi: 10.1038/s41467-023-41698-5
-
[10]
Z. Zhong, et al., WIREs Comput. Mol. Sci. 14 (2023) e1694.
-
[11]
J. Dong, M. Zhao, Y. Liu, Y. Su, X. Zeng, Brief Bioinform. 23 (2022) bbab391.
-
[12]
S. Zheng, J. Rao, Z. Zhang, J. Xu, Y. Yang, J. Chem. Inf. Model. 60 (2019) 47–55. doi: 10.1504/ijiids.2019.10023833
-
[13]
C.W. Coley, R. Barzilay, T.S. Jaakkola, et al., ACS Cent. Sci. 3 (2017) 434–443. doi: 10.1021/acscentsci.7b00064
-
[14]
C.W. Coley, L. Rogers, W.H. Green, K.F. Jensen, ACS Cent. Sci. 3 (2017) 1237–1245. doi: 10.1021/acscentsci.7b00355
-
[15]
P. Karpov, G. Godin, I.V. Tetko, Chapter 78, artificial neural networks and machine learning – ICANN 2019: workshop and special sessions, Lecture Notes in Computer Science, Springer, 2019, pp. 817–830.
-
[16]
K. Lin, Y. Xu, J. Pei, L. Lai, Chem. Sci. 11 (2020) 3355–3364. doi: 10.1039/c9sc03666k
-
[17]
P. Schwaller, T. Laino, T. Gaudin, et al., ACS Cent. Sci. 5 (2019) 1572–1583. doi: 10.1021/acscentsci.9b00576
-
[18]
M. Sacha, M. Błaz, P. Byrski, et al., J. Chem. Inf. Model. 61 (2021) 3273–3284. doi: 10.1021/acs.jcim.1c00537
-
[19]
J. Lu, Y. Zhang, J. Chem. Inf. Model. 62 (2022) 1376–1387. doi: 10.1021/acs.jcim.1c01467
-
[20]
B. Liu, B. Ramsundar, P. Kawthekar, et al., ACS Cent. Sci. 3 (2017) 1103–1113. doi: 10.1021/acscentsci.7b00303
-
[21]
C. Shi, M. Xu, H. Guo, M. Zhang, J. Tang, arXiv: (2021),
https://doi.org/10.48550/arXiv.2003.12725 . -
[22]
Z. Tu, C.W. Coley, J. Chem. Inf. Model. 62 (2022) 3503–3513. doi: 10.1021/acs.jcim.2c00321
-
[23]
I.V. Tetko, P. Karpov, R. Van Deursen, et al., Nat. Commun. 11 (2020) 5575. doi: 10.1038/s41467-020-19266-y
-
[24]
Z. Zhong, J. Song, Z. Feng, et al., Chem. Sci. 13 (2022) 9023–9034. doi: 10.1039/d2sc02763a
-
[25]
A.A. Lee, Q. Yang, V. Sresht, et al., Chem. Commun. 55 (2019) 12152–12155. doi: 10.1039/c9cc05122h
-
[26]
W. Qian, X. Wang, Y. Kang, et al., J. Cheminform. 16 (2024) 38. doi: 10.1186/s13321-024-00827-y
-
[27]
E. Heid, D. Probst, W.H. Green, et al., Chem. Sci. 14 (2023) 14229–14242. doi: 10.1039/d3sc02048g
-
[28]
T.W. Thorpe, J.R. Marshall, N.J. Turner, J. Am. Chem. Soc. 146 (2024) 7876–7884. doi: 10.1021/jacs.3c09542
-
[29]
D. Kreutter, P. Schwaller, J.L. Reymond, Chem. Sci. 12 (2021) 8648–8659. doi: 10.1039/d1sc02362d
-
[30]
D. Probst, M. Manica, Y.G.N. Teukam, et al., Nat. Commun. 13 (2022) 964. doi: 10.1038/s41467-022-28536-w
-
[31]
T.T.V. Tran, H. Tayara, K.T. Chong, Pharmaceutics 15 (2023) 1260. doi: 10.3390/pharmaceutics15041260
-
[32]
Z. Chen, L. Zhang, P. Zhang, et al., J. Chem. Inf. Model. 64 (2024) 2528–2538. doi: 10.1021/acs.jcim.3c01396
-
[33]
J.D. Tyzack, J. Kirchmair, Chem. Biol. Drug Des. 93 (2019) 377–386. doi: 10.1111/cbdd.13445
-
[34]
Y. Djoumbou-Feunang, J. Fiamoncini, A. Gil-de-la-Fuente, et al., J. Cheminform. 11 (2019) 2. doi: 10.1186/s13321-018-0324-5
-
[35]
J. Hafner, V. Hatzimanikatis, Bioinformatics 37 (2021) 3560–3568. doi: 10.1093/bioinformatics/btab368
-
[36]
D. Wang, W. Liu, Z. Shen, et al., Front. Pharmacol. 10 (2019) 1586. doi: 10.1007/s10114-019-8312-x
-
[37]
E.E. Litsa, P. Das, L.E. Kavraki, Chem. Sci. 11 (2020) 12777–12788. doi: 10.1039/d0sc02639e
-
[38]
M. Lewis, Y. Liu, N. Goyal, et al., arXiv (2019),
https://doi.org/10.48550/arXiv.1910.13461 . -
[39]
C. Choudhury, V. Kumar, R. Kumar, Eur. J. Med. Chem. 249 (2023) 115153. doi: 10.1016/j.ejmech.2023.115153
-
[40]
S.W. Seo, Y.Y. Song, J.Y. Yang, et al., GTA: Graph truncated attention for retrosynthesis, in: Proceedings of the AAAI Conference on Artificial Intelligence, 35, 2021, pp. 531–539.
-
[1]
-
Figure 1 The model's prediction accuracies in the forward and backward modes for different reaction classes.
Scheme 1 Multistep retrosyntheses of (a) indomethacin and (b) bambuterol and (c) multistep retrosynthesis and (d) forward prediction of osimertinib.
Scheme 2 Single-step retrosynthetic analysis and metabolic prediction of small-molecule drugs.
Scheme 3 Analysis of single-step retrosynthesis and prediction of enzyme-catalyzed reactions of natural products.
Table 1. Ablation experiments of BiCINet for USPTO_50 K dataset.
Mode Class Batch size Task_percenta Flag_dualb Learning_rate Top1_accuracy (%) Bc FALSE 32 1.0 TRUE 5.00E−05 40.8 B FALSE 32 0.5 TRUE 5.00E−05 42.1 B TRUE 64 1.0 TRUE 1.00E−04 51.5 B TRUE 64 0.5 TRUE 1.00E−04 54.0 Fd FALSE 64 1.0 FALSE 1.00E−04 76.1 F FALSE 64 1.0 TRUE 1.00E−04 80.7 a "Task_percent" = 1.0 implies no masking. Task_percent = 0.5 implies a 50% probability for masking products.
b "Flag_dual" = True implies bidirectional training will be performed on both reactants and products.
c B means backward.
d F means forward. 下载: 导出CSV
下载: 导出CSV
Table 2. Performance of BiCINet framework for the USPTO_50 K dataset.
Top-K 50K_Backward 50K_Forward Accuracy (%) Max_accuracy (%) Accuracy (%) Max_accuracy (%) 1 48.6 52.9 80.7 86.2 3 64.9 70.1 88.3 92.6 5 69.4 75.5 89.7 94.0 10 73.9 81.6 91.1 95.2 50 82.1 88.3 93.7 96.3 100 85.9 88.8 95.1 96.4
下载: 导出CSV
Table 3. Performance of BiCINet framework for the USPTO_50K_class dataset.
Top-K 50K_Backward 50K_Forward Accuracy (%) Max_accuracy (%) Accuracy (%) Max_accuracy (%) 1 62.2 66.6 82.8 90.1 3 77.0 81.6 87.8 95.8 5 80.3 85.9 88.7 96.7 10 83.0 89.8 89.6 97.5 50 90.0 93.3 91.2 98.3 100 93.1 93.4 91.6 98.3
下载: 导出CSV
-













 扫一扫看文章
扫一扫看文章
计量
- PDF下载量: 0
- 文章访问数: 726
- HTML全文浏览量: 29
 下载:
下载:
